Data File Downloads¶
Users can download data files associated with a study by downloading the files directly from the Discovery page, or leveraging the CTDS-owned python software development kit (SDK) and the tool “Gen3-client” if the file size exceeds 250 MB.
Note that current studies that have datasets of more than 250 MB are those with the following project numbers: a) cdcwonder and b) deaarcos1.
Note, that accessing data files requires linked access to all FAIR enabled repositories, as described here. A pop-up window will remind users:
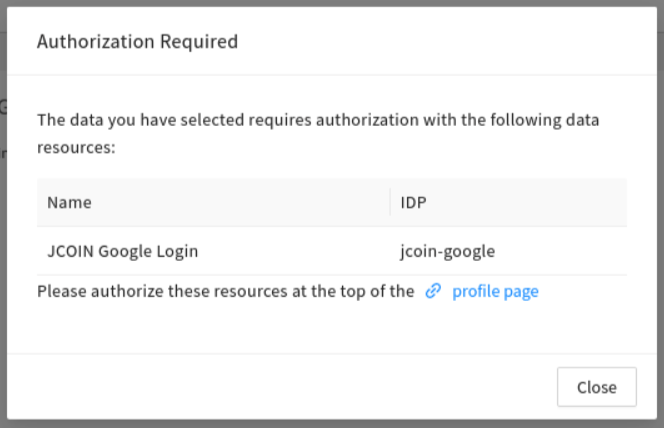
Users are reminded to link the account to all other FAIR enabled repositories, as described here.
Download Data Files from the Discovery Page¶
Users can download data files up to sizes of 250 MB directly from the Discovery Page.
Below you find the simple steps to do so.
-
Navigate to the Discovery Page. Link your accounts to FAIR repositories as described here.
-
Find the study of interest by using the search features or the list of accessible studies.
-
Select the clickable box next to the study.
Click on "Download ZIP", which will initiate the data download.
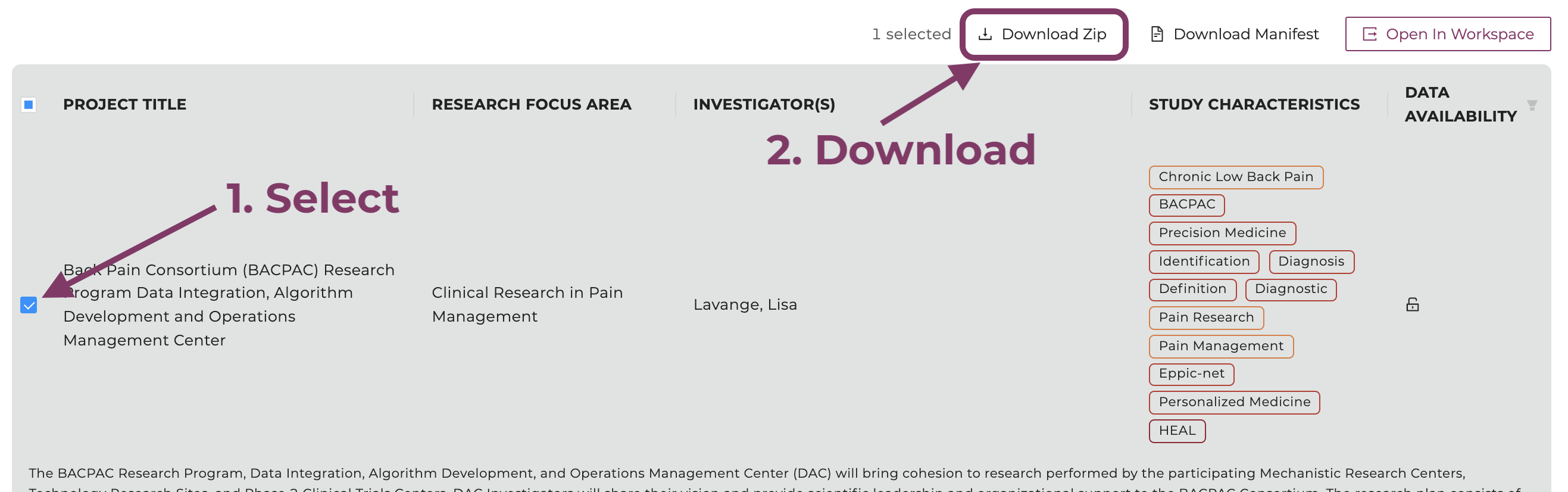
Select the study and click "Download ZIP".
-
Users will be prompted with a window that shows the download is being prepared.
Please do not navigate away from this page until the download is complete.
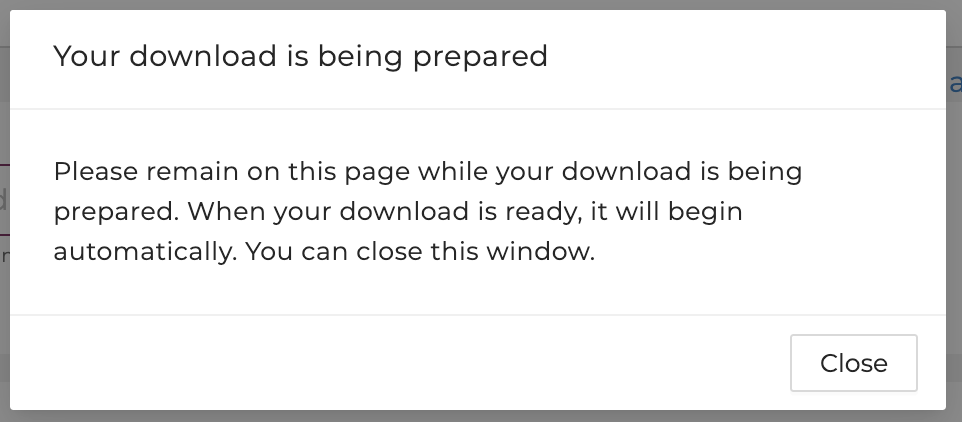
After clicking "Download ZIP", your download is being prepared. Please do not navigate away from this page until the download is complete.
-
Users will be notified once the download is ready. If the download doesn't start automatically, please follow the link prompted.
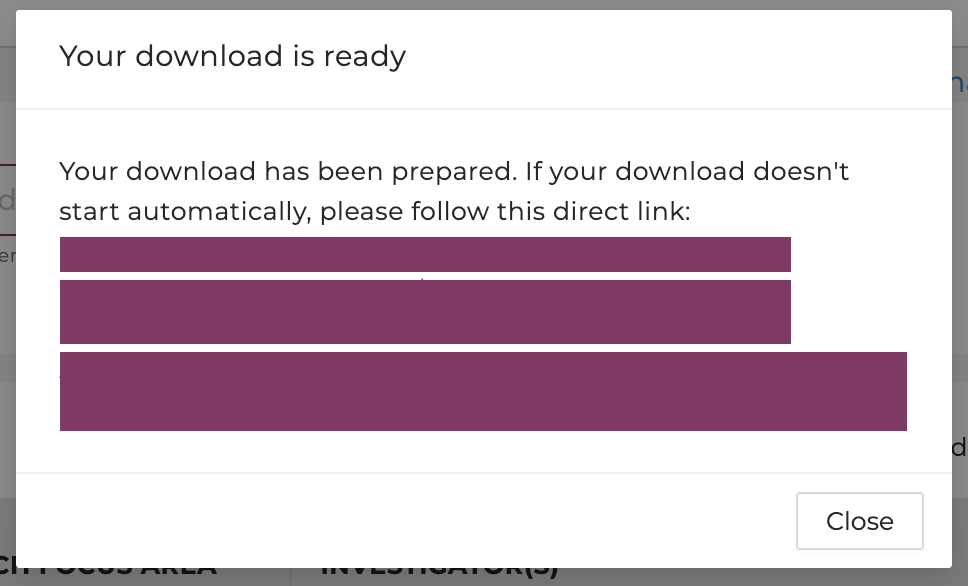
Users will be notified once the download is ready. Save the file(s) by selecting the directory using the prompted window.
-
If the file size exceeds 250 MB, users will be notified to deselect studies to reduce the size or use other tools:
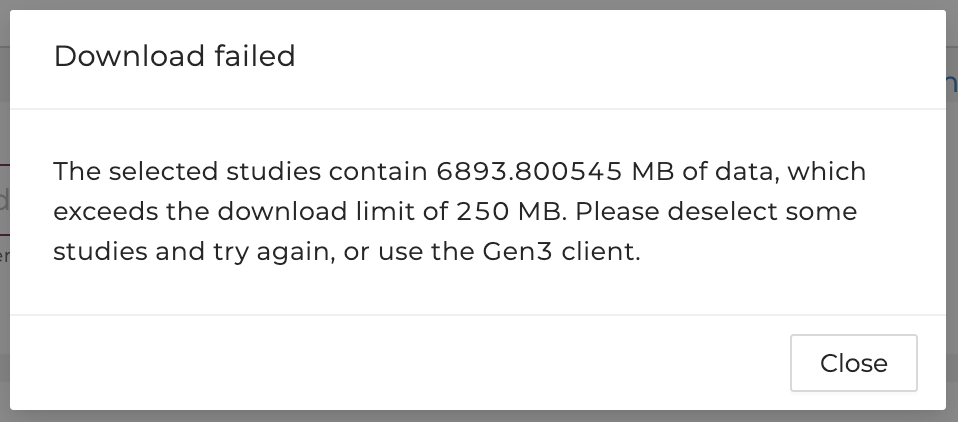
Users are advised to use other tools to download the files if the total file size exceeds 250 MB. Please see the next section for a step-by-step guide using these tools.
Download Data Files using the Gen3-client¶
In order to download data files above 250 MB, users will need to utilize the Gen3-client command line tool developed by the University of Chicago’s Center for Translational Data Science.
The current studies that have datasets of more than 250 MB are those with the following project numbers: a) cdcwonder and b) deaarcos1.
Find below a guide to download data files using the Gen3-client:
-
Log in to the HEAL Platform at https://healdata.org/portal/login. Link your accounts to FAIR repositories as described here.
-
Find and select one or multiple studies of interest on the Discovery Page. For multiple studies, select "Data Availability" in the top right corner, click “Available”, and choose multiple studies.
-
Click on the button “Download Manifest".
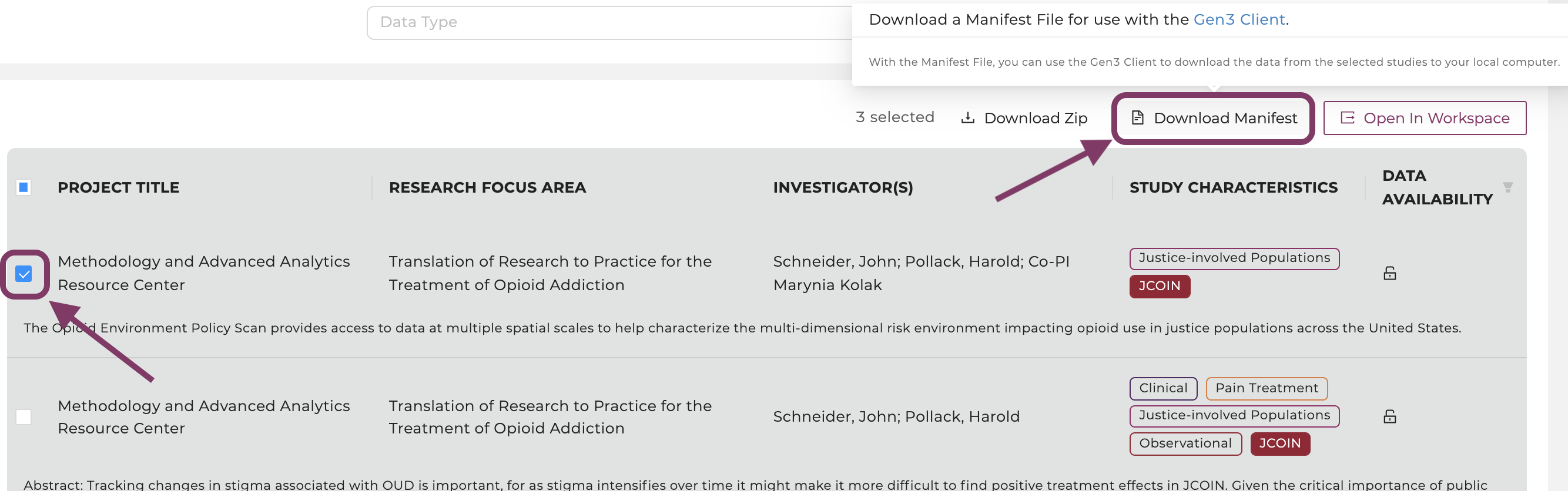
Select a study of interest, then click on the button “Download Manifest".
- Create and download an API key from your Profile Page. Note where you save the API key on your local machine.

Create an API key on the profile page.
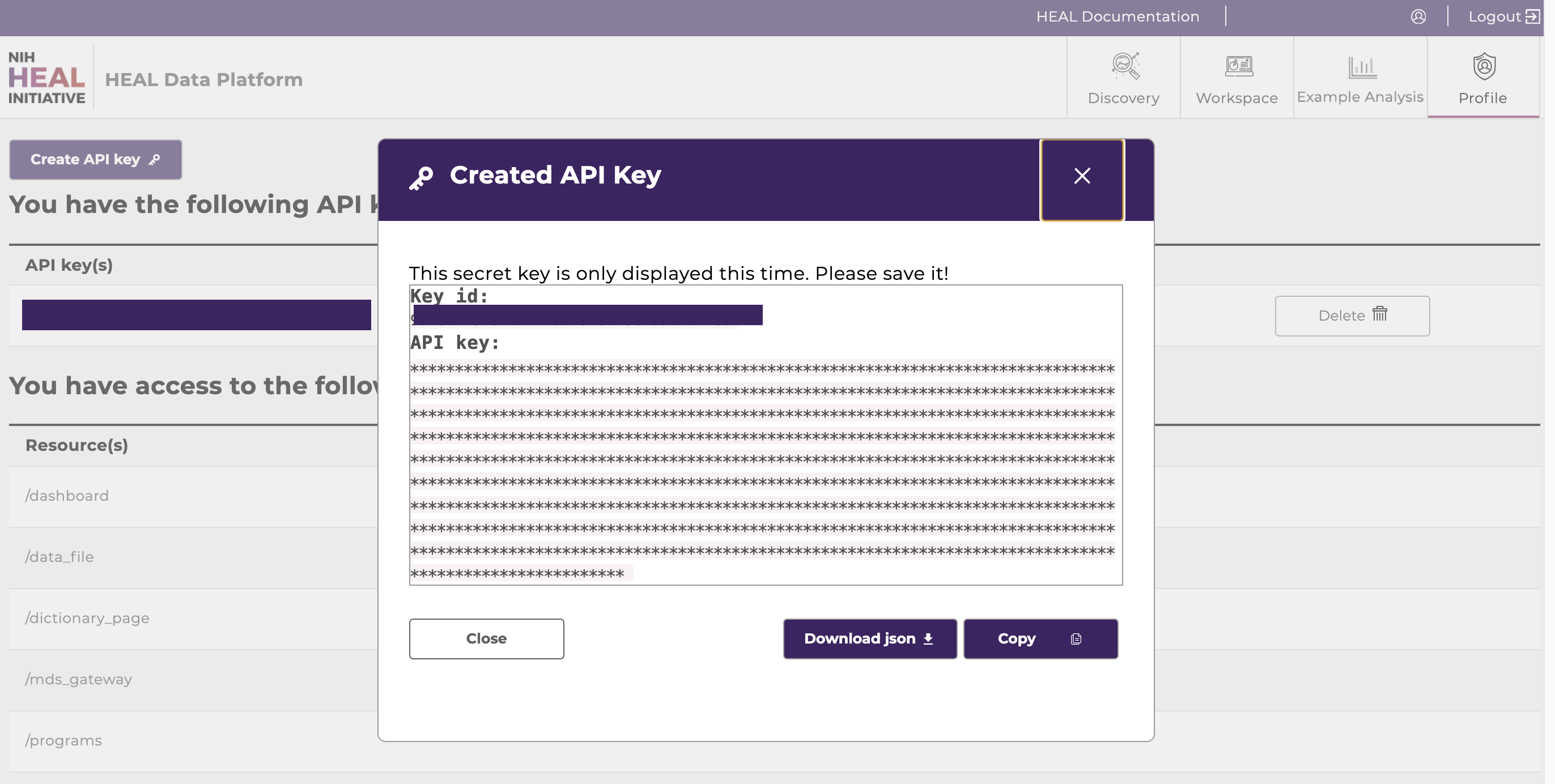
Download the API key as json file and note the directory where the API key was saved for step 6.
-
Download and configure the Gen3-client
a. Follow the download instructions of the Gen3-client here. The client can be downloaded here.b. In your terminal, configure your profile using the following command:
gen3-client configure --profile=<profile_name> --cred=<credentials.json> --apiendpoint=<api_endpoint_url>`Mac/Linux:
gen3-client configure --profile=demo --cred=~/Downloads/demo-credentials.json --apiendpoint=https://healdata.org/Windows:
gen3-client configure --profile=demo --cred=C:\Users\demo\Downloads\demo-credentials.json --apiendpoint=https://healdata.org/If the command was succesful, you should get the following output:
10:08:20 Profile 'demo' has been configured successfully.If successfully executed, a configuration file will be stored under the directory the user specified under “cred”. For troubleshooting, refer to the instructions found here.
c. Download files by using the following command, which references the manifest file name and its location:
For example:gen3-client download-multiple --profile=<profile_name> --manifest=<manifest_file> --download-path=<path_for_files>gen3-client download-multiple --profile=demo --manifest=manifest.json --download-path=downloads2021/06/03 16:48:46 Reading manifest... 200 B / 200 B [===================] 100.00% 0s WARNING: flag "rename" was set to false in "original" mode, duplicated files under "downloads/" will be overwritten Proceed? [y/n]:Enter:
yOutput:
2021/06/03 16:48:47 Total number of GUIDs: 1 2021/06/03 16:48:47 Preparing file info for each file, please wait... 1 / 1 [============================================] 100.00% 0s 2021/06/03 16:48:47 File info prepared successfully arcos_all_washpost.tsv.gz 6.41 GiB / 6.41 GiB [=======================================================] 100.00% 0s
Download Data Files in Workspaces using the Python SDK¶
Users can download data files to the workspaces by leveraging the CTDS-owned python software development kit (SDK). Follow instructions below.
-
Log in to the Data Commons at https://healdata.org/portal/login. Link your accounts to FAIR repositories as described here.
-
Find and select one or multiple studies of interest on the Discovery Page. Select "Data Availability" in the top right corner and click on “Available” to see all available studies.
-
Select a study and click on "Open in Workspace".
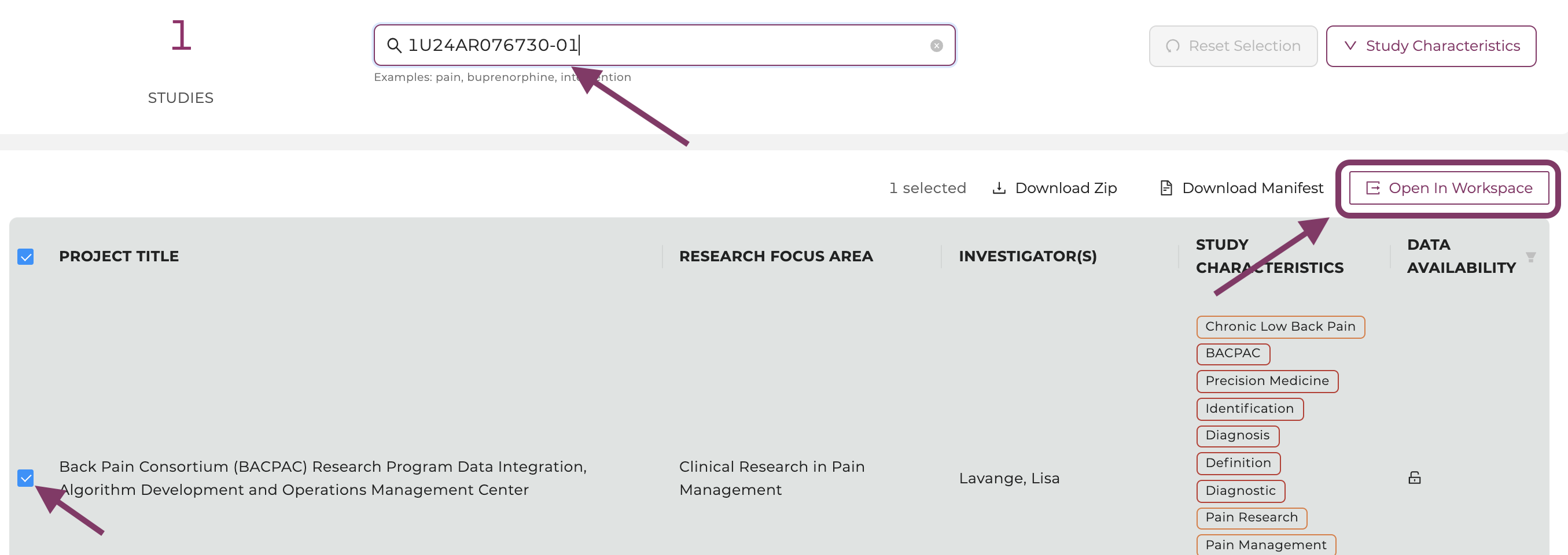
-
Select a workspace VM and click "Launch". Choose the "(Generic) Jupyter Notebook with R kernel" if you are familiar with setting up Python- or R-based Notebooks, or if you just exported one or multiple studies from the Discovery Page and want to start your custom analysis. Choose a VM with the name of the Notebook if you selected the studies relevant to a specific Notebook and want to work on the Notebook in interactive mode.
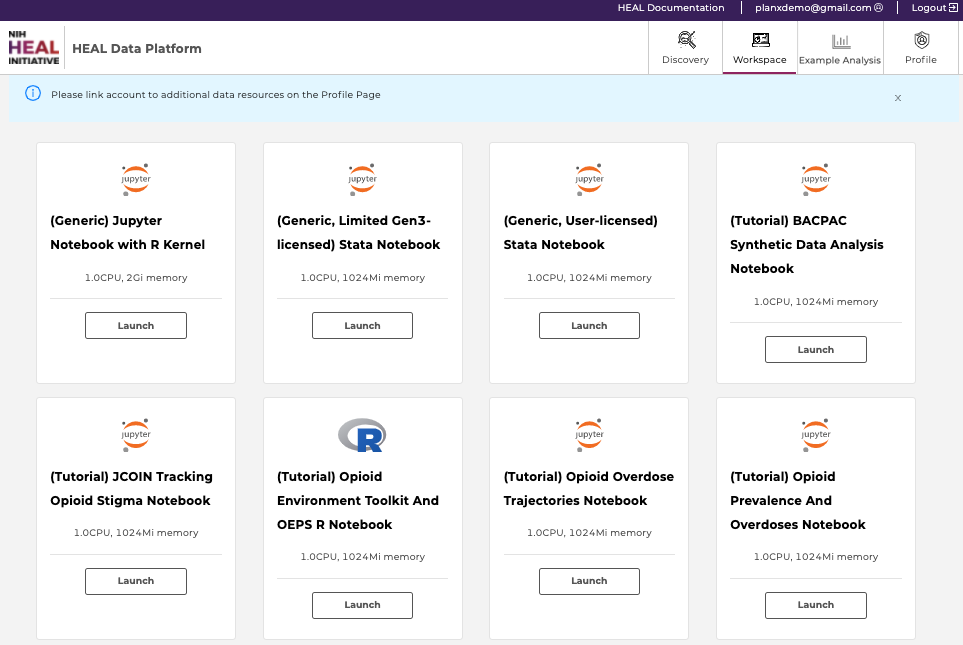
Available workspaces on the HEAL Platform (top). Users need to link accounts from other repositories (bottom; click here to see how).
-
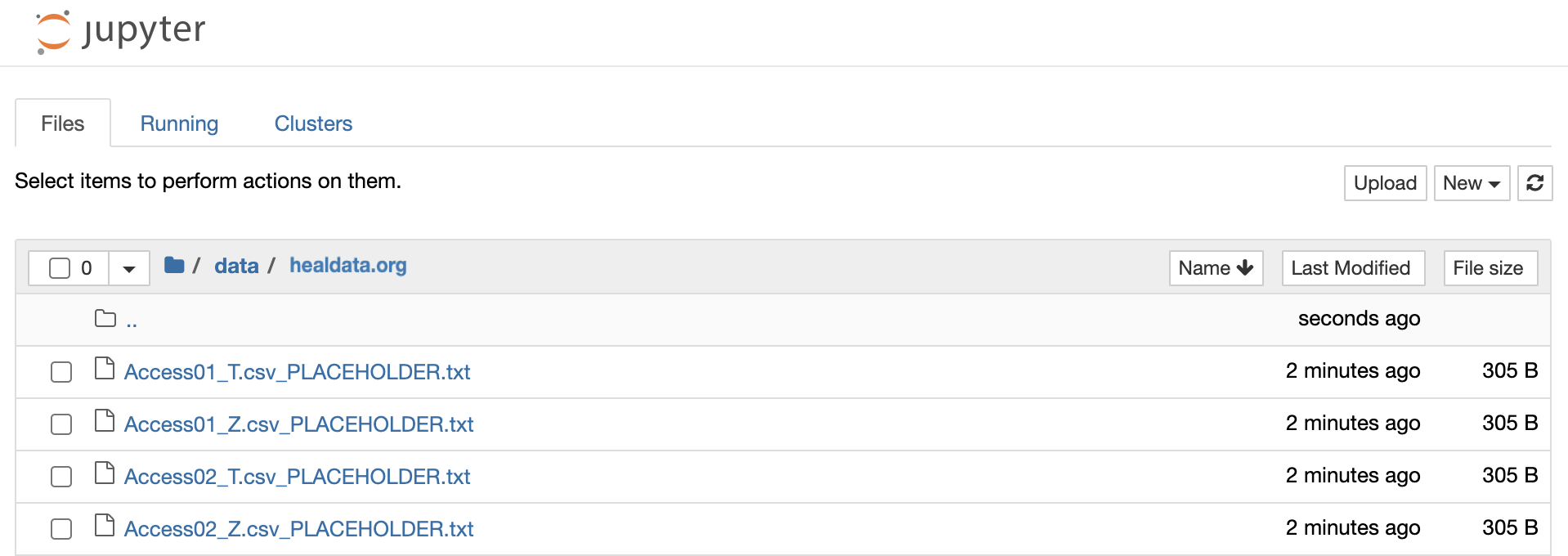
Find all files under /data/healdata.org/ with the ending "PLACEHOLDER". These files can be directly downloaded either in the terminal or in a notebook cell.
-
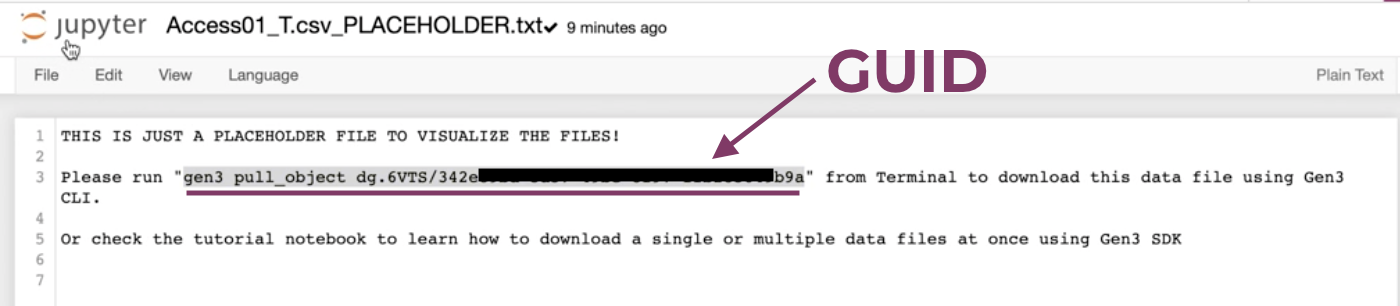
Click on one file and copy the command and GUID.
-
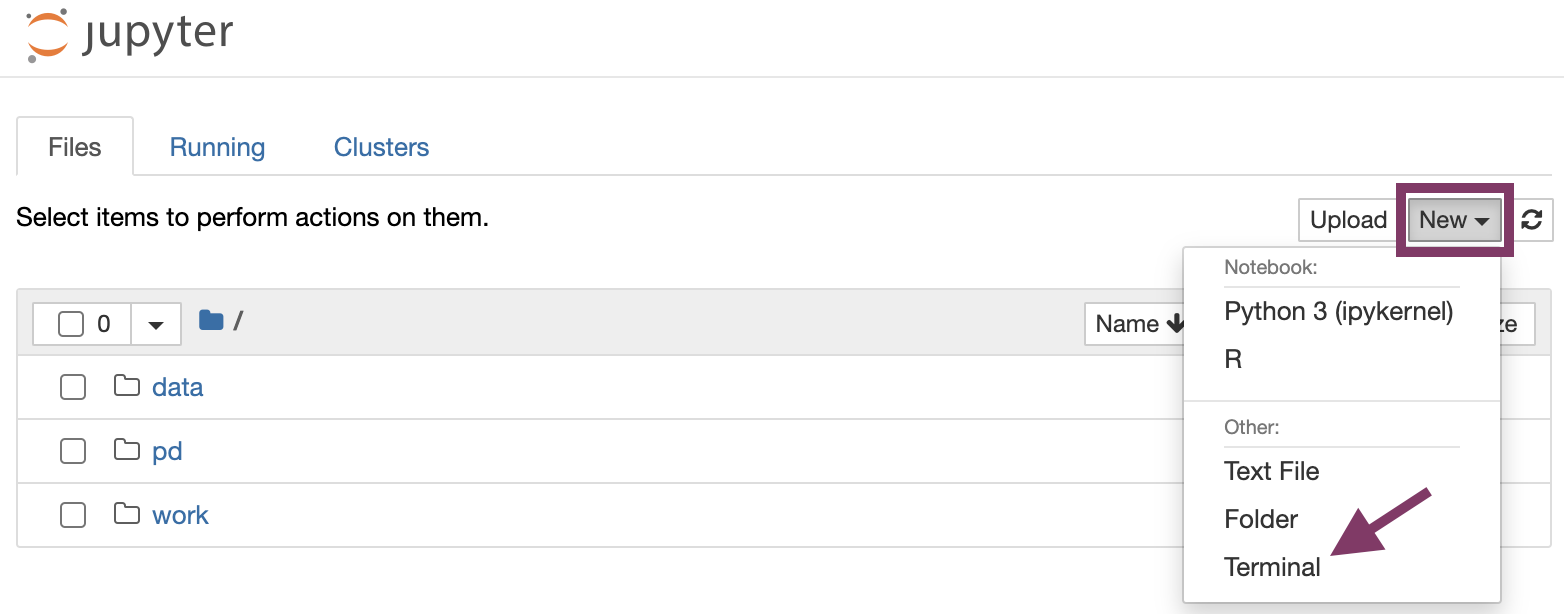
Open a new terminal under "New".
-
- Type in the following command to download the file to the terminal:
gen3 drs-pull object "guid"
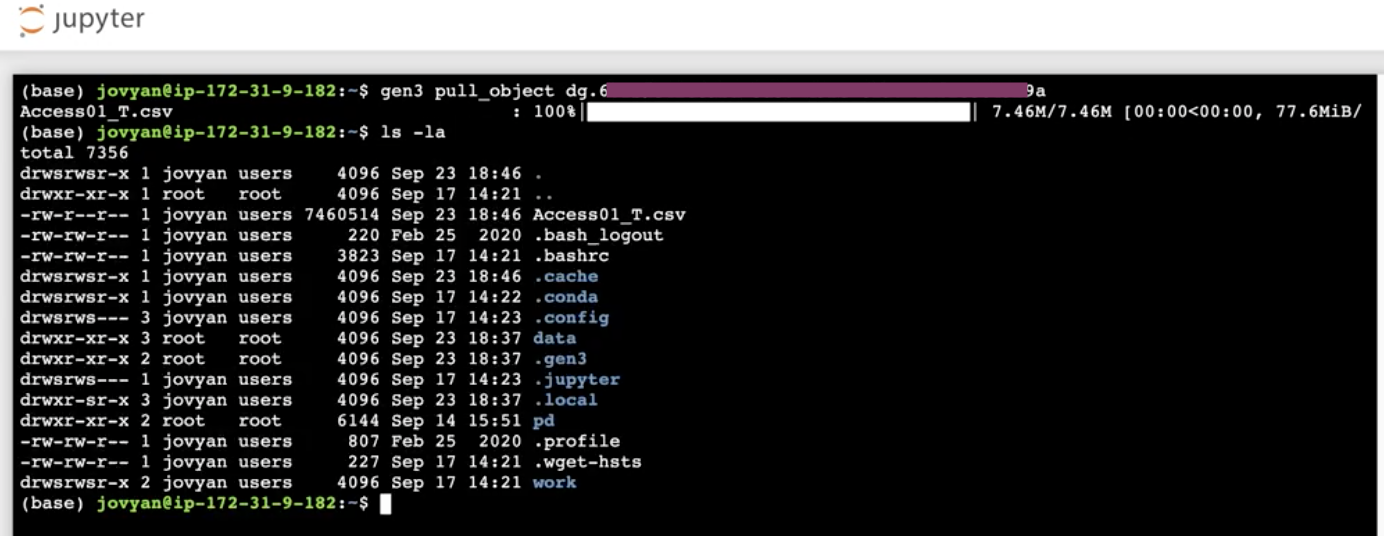
- If you are working in a notebook, type in the following command into a code cell to download the file:
!gen3 drs-pull object "guid"
-
If you use the R kernel, change the command into
system("gen3 drs-pull object 'guid'") -
Note, that you can also use the manifest.json to download in batches, see below:

Download files in batches with a file manifest using the commands shown above.
- Type in the following command to download the file to the terminal:
-
The file(s) should be downloaded and is ready to be worked with in your Notebook.
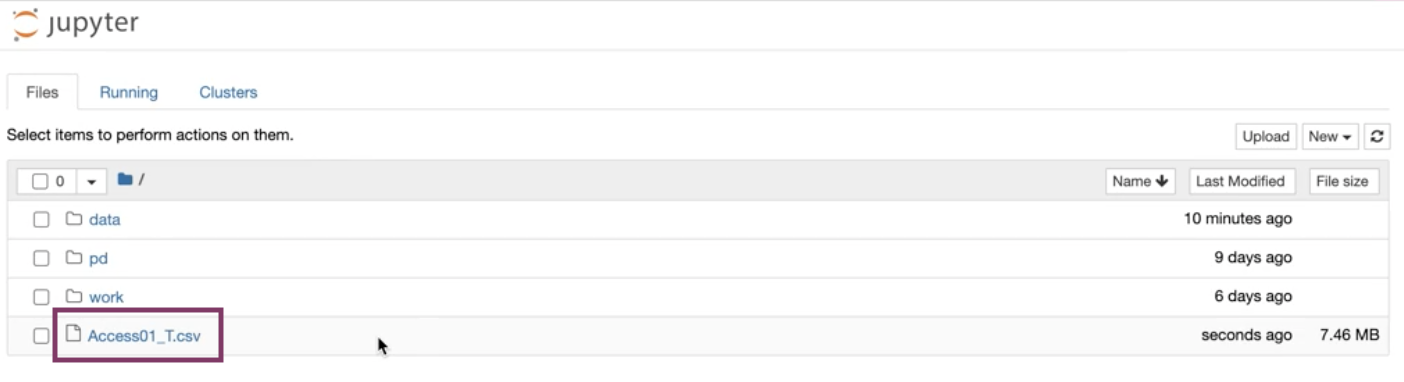
Downloaded files can be found in your home directory.